Однофакторный дисперсионный анализ. Пример решения. Введение в дисперсионный анализ
Чтобы проанализировать изменчивость признака под воздействием контролируемых переменных, применяется дисперсионный метод.
Для изучения связи между значениями – факторный метод. Рассмотрим подробнее аналитические инструменты: факторный, дисперсионный и двухфакторный дисперсионный метод оценки изменчивости.
Дисперсионный анализ в Excel
Условно цель дисперсионного метода можно сформулировать так: вычленить из общей вариативности параметра 3 частные вариативности:
- 1 – определенную действием каждого из изучаемых значений;
- 2 – продиктованную взаимосвязью между исследуемыми значениями;
- 3 – случайную, продиктованную всеми неучтенными обстоятельствами.
В программе Microsoft Excel дисперсионный анализ можно выполнить с помощью инструмента «Анализ данных» (вкладка «Данные» - «Анализ»). Это надстройка табличного процессора. Если надстройка недоступна, нужно открыть «Параметры Excel» и включить настройку для анализа .
Работа начинается с оформления таблицы. Правила:
- В каждом столбце должны быть значения одного исследуемого фактора.
- Столбцы расположить по возрастанию/убыванию величины исследуемого параметра.
Рассмотрим дисперсионный анализ в Excel на примере.
Психолог фирмы проанализировал с помощью специальной методики стратегии поведения сотрудников в конфликтной ситуации. Предполагается, что на поведение влияет уровень образования (1 – среднее, 2 – среднее специальное, 3 – высшее).
Внесем данные в таблицу Excel:


Значимый параметр залит желтым цветом. Так как Р-Значение между группами больше 1, критерий Фишера нельзя считать значимым. Следовательно, поведение в конфликтной ситуации не зависит от уровня образования.
Факторный анализ в Excel: пример
Факторным называют многомерный анализ взаимосвязей между значениями переменных. С помощью данного метода можно решить важнейшие задачи:
- всесторонне описать измеряемый объект (причем емко, компактно);
- выявить скрытые переменные значения, определяющие наличие линейных статистических корреляций;
- классифицировать переменные (определить взаимосвязи между ними);
- сократить число необходимых переменных.
Рассмотрим на примере проведение факторного анализа. Допустим, нам известны продажи каких-либо товаров за последние 4 месяца. Необходимо проанализировать, какие наименования пользуются спросом, а какие нет.


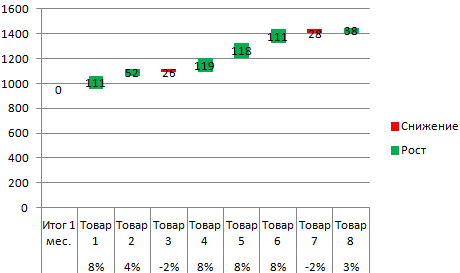
Теперь наглядно видно, продажи какого товара дают основной рост.
Двухфакторный дисперсионный анализ в Excel
Показывает, как влияет два фактора на изменение значения случайной величины. Рассмотрим двухфакторный дисперсионный анализ в Excel на примере.
Задача. Группе мужчин и женщин предъявляли звук разной громкости: 1 – 10 дБ, 2 – 30 дБ, 3 – 50 дБ. Время ответа фиксировали в миллисекундах. Необходимо определить, влияет ли пол на реакцию; влияет ли громкость на реакцию.
Однофакторная дисперсионная модель имеет вид
где Xjj - значение исследуемой переменной, полученной на г-м уровне фактора (г = 1, 2,..., т) су-м порядковым номером (j- 1,2,..., п); /у - эффект, обусловленный влиянием г-го уровня фактора; е^. - случайная компонента, или возмущение, вызванное влиянием неконтролируемых факторов, т.е. вариацией переменной внутри отдельного уровня.
Под уровнем фактора понимается некоторая его мера или состояние, например, количество вносимых удобрений, вид плавки металла или номер партии деталей и т.п.
Основные предпосылки дисперсионного анализа.
1. Математическое ожидание возмущения ? (/ - равно нулю для любых i, т.е.
- 2. Возмущения взаимно независимы.
- 3. Дисперсия возмущения (или переменной Ху) постоянна для любых ij> т.е.
4. Возмущение е# (или переменная Ху) имеет нормальный закон распределения N( 0; а 2).
Влияние уровней фактора может быть как фиксированным , или систематическим (модель I), так и случайным (модель II).
Пусть, например, необходимо выяснить, имеются ли существенные различия между партиями изделий по некоторому показателю качества, т.е. проверить влияние на качество одного фактора - партии изделий. Если включить в исследование все партии сырья, то влияние уровня такого фактора систематическое (модель I), а полученные выводы применимы только к тем отдельным партиям, которые привлекались при исследовании; если же включить только отобранную случайно часть партий, то влияние фактора случайное (модель II). В многофакторных комплексах возможна смешанная модель III, в которой одни факторы имеют случайные уровни, а другие - фиксированные.
Рассмотрим эту задачу подробнее. Пусть имеется т партий изделий. Из каждой партии отобрано соответственно п Л, п 2 ,п т изделий (для простоты полагаем, что щ = п 2 =... = п т = п). Значения показателя качества этих изделий представим в виде матрицы наблюдений

Необходимо проверить существенность влияния партий изделий на их качество.
Если полагать, что элементы строк матрицы наблюдений - это численные значения (реализации) случайных величин X t , Х 2 ,..., Х т, выражающих качество изделий и имеющих нормальный закон распределения с математическими ожиданиями соответственно a v а 2 , ..., а т и одинаковыми дисперсиями а 2 , то данная задача сводится к проверке нулевой гипотезы # 0: a v = a 2l = ... = а т,осуществляемой в дисперсионном анализе.
Обозначим усреднение по какому-либо индексу звездочкой (или точкой) вместо индекса, тогда средний показатель качества изделий г’-й партии, или групповая средняя для г-го уровня фактора, примет вид
а общая средняя
-

Рассмотрим сумму квадратов отклонений наблюдений от общей средней х„:

или Q = Q, + Q 2 + ?>з Последнее слагаемое
так как сумма отклонений значений переменной от ее средней, т.е. ? 1.г у - х) равна нулю. ) =х
Первое слагаемое можно записать в виде
В результате получим следующее тождество:
т п. _
где Q = Y, X [ х ij _ х„, I 2 - общая, или полная, сумма квадратов отклонений; 7=1
Q, - n^}