Формула бернулли применяется для определения вероятности. Повторные независимые испытания схема и формула бернулли
Определение повторных независимых испытаний. Формулы Бернулли для вычисления вероятности и наивероятнейшего числа. Асимптотические формулы для формулы Бернулли (локальная и интегральная, теоремы Лапласа). Использование интегральной теоремы. Формула Пуассона, для маловероятных случайных событий.
Повторные независимые испытания
На практике приходится сталкиваться с такими задачами, которые можно представить в виде многократно повторяющихся испытаний, в результате каждого из которых может появиться или не появиться событие A . При этом интерес представляет исход не каждого "отдельного испытания, а общее количество появлений события A в результате определенного количества испытаний. В подобных задачах нужно уметь определять вероятность любого числа m появлений события A в результате n испытаний. Рассмотрим случай, когда испытания являются независимыми и вероятность появления события A в каждом испытании постоянна. Такие испытания называются повторными независимыми.
Примером независимых испытаний может служить проверка на годность изделий, взятых по одному из ряда партий. Если в этих партиях процент брака одинаков, то вероятность того, что отобранное изделие будет бракованным, в каждом случае является постоянным числом.
Формула Бернулли
Воспользуемся понятием сложного события , под которым подразумевается совмещение нескольких элементарных событий, состоящих в появлении или непоявлении события A в i –м испытании. Пусть проводится n независимых испытаний, в каждом из которых событие A может либо появиться с вероятностью p , либо не появиться с вероятностью q=1-p . Рассмотрим событие B_m , состоящее в том, что событие A в этих n испытаниях наступит ровно m раз и, следовательно, не наступит ровно (n-m) раз. Обозначим A_i~(i=1,2,\ldots,{n}) появление события A , a \overline{A}_i - непоявление события A в i –м испытании. В силу постоянства условий испытания имеем
Событие A может появиться m раз в разных последовательностях или комбинациях, чередуясь с противоположным событием \overline{A} . Число возможных комбинаций такого рода равно числу сочетаний из n элементов по m , т. е. C_n^m . Следовательно, событие B_m можно представить в виде суммы сложных несовместных между собой событий, причем число слагаемых равно C_n^m :
B_m=A_1A_2\cdots{A_m}\overline{A}_{m+1}\cdots\overline{A}_n+\cdots+\overline{A}_1\overline{A}_2\cdots\overline{A}_{n-m}A_{n-m+1}\cdots{A_n},
где в каждое произведение событие A входит m раз, а \overline{A} - (n-m) раз.
Вероятность каждого сложного события, входящего в формулу (3.1), по теореме умножения вероятностей для независимых событий равна p^{m}q^{n-m} . Так как общее количество таких событий равно C_n^m , то, используя теорему сложения вероятностей для несовместных событий, получаем вероятность события B_m (обозначим ее P_{m,n} )
P_{m,n}=C_n^mp^{m}q^{n-m}\quad \text{or}\quad P_{m,n}=\frac{n!}{m!(n-m)!}p^{m}q^{n-m}.
Формулу (3.2) называют формулой Бернулли , а повторяющиеся испытания, удовлетворяющие условию независимости и постоянства вероятностей появления в каждом из них события A , называют испытаниями Бернулли , или схемой Бернулли .
Пример 1. Вероятность выхода за границы поля допуска при обработке деталей на токарном станке равна 0,07. Определить вероятность того, что из пяти наудачу отобранных в течение смены деталей у одной размеры диаметра не соответствуют заданному допуску.
Решение. Условие задачи удовлетворяет требования схемы Бернулли. Поэтому, полагая n=5,\,m=1,\,p=0,\!07 , по формуле (3.2) получаем
P_{1,5}=C_5^1(0,\!07)^{1}(0,\!93)^{5-1}\approx0,\!262.
Пример 2. Наблюдениями установлено, что в некоторой местности в сентябре бывает 12 дождливых дней. Какова вероятность того, что из случайно взятых в этом месяце 8 дней 3 дня окажутся дождливыми?
Решение.
P_{3;8}=C_8^3{\left(\frac{12}{30}\right)\!}^3{\left(1-\frac{12}{30}\right)\!}^{8-3}=\frac{8!}{3!(8-3)!}{\left(\frac{2}{5}\right)\!}^3{\left(\frac{3}{5}\right)\!}^5=56\cdot\frac{8}{125}\cdot\frac{243}{3125}=\frac{108\,864}{390\,625}\approx0,\!2787.
Наивероятнейшее число появлений события
Наивероятнейшим числом появления события A в n независимых испытаниях называется такое число m_0 , для которого вероятность, соответствующая этому числу, превышает или, по крайней мере, не меньше вероятности каждого из остальных возможных чисел появления события A . Для определения наивероятнейшего числа не обязательно вычислять вероятности возможных чисел появлений события, достаточно знать число испытаний n и вероятность появления события A в отдельном испытании. Обозначим P_{m_0,n} вероятность, соответствующую наивероятнейшему числу m_0 . Используя формулу (3.2), записываем
P_{m_0,n}=C_n^{m_0}p^{m_0}q^{n-m_0}=\frac{n!}{m_0!(n-m_0)!}p^{m_0}q^{n-m_0}.
Согласно определению наивероятнейшего числа, вероятности наступления события A соответственно m_0+1 и m_0-1 раз должны, по крайней мере, не превышать вероятность P_{m_0,n} , т. е.
P_{m_0,n}\geqslant{P_{m_0+1,n}};\quad P_{m_0,n}\geqslant{P_{m_0-1,n}}
Подставляя в неравенства значение P_{m_0,n} и выражения вероятностей P_{m_0+1,n} и P_{m_0-1,n} , получаем
Решая эти неравенства относительно m_0 , получаем
M_0\geqslant{np-q},\quad m_0\leqslant{np+p}
Объединяя последние неравенства, получаем двойное неравенство, которое используют для определения наивероятнейшего числа:
Np-q\leqslant{m_0}\leqslant{np+p}.
Так как длина интервала, определяемого неравенством (3.4), равна единице, т. е.
(np+p)-(np-q)=p+q=1,
и событие может произойти в n испытаниях только целое число раз, то следует иметь в виду, что:
1) если np-q - целое число, то существуют два значения наивероятнейшего числа, а именно: m_0=np-q и m"_0=np-q+1=np+p ;
2) если np-q - дробное число, то существует одно наивероятнейшее число, а именно: единственное целое, заключенное между дробными числами, полученными из неравенства (3.4);
3) если np - целое число, то существует одно наивероятнейшее число, а именно: m_0=np .
При больших значениях n пользоваться формулой (3.3) для расчета вероятности, соответствующей наивероятнейшему числу, неудобно. Если в равенство (3.3) подставить формулу Стирлинга
N!\approx{n^ne^{-n}\sqrt{2\pi{n}}},
справедливую для достаточно больших n , и принять наивероятнейшее число m_0=np , то получим формулу для приближенного вычисления вероятности, соответствующей наивероятнейшему числу:
P_{m_0,n}\approx\frac{n^ne^{-n}\sqrt{2\pi{n}}\,p^{np}q^{nq}}{(np)^{np}e^{-np}\sqrt{2\pi{np}}\,(nq)^{nq}e^{-nq}\sqrt{2\pi{nq}}}=\frac{1}{\sqrt{2\pi{npq}}}=\frac{1}{\sqrt{2\pi}\sqrt{npq}}.
Пример 2. Известно, что \frac{1}{15} часть продукции, поставляемой заводом на торговую базу, не удовлетворяет всем требованиям стандарта. На базу была завезена партия изделий в количестве 250 шт. Найти наивероятнейшее число изделий, удовлетворяющих требованиям стандарта, и вычислить вероятность того, что в этой партии окажется наивероятнейшее число изделий.
Решение. По условию n=250,\,q=\frac{1}{15},\,p=1-\frac{1}{15}=\frac{14}{15} . Согласно неравенству (3.4) имеем
250\cdot\frac{14}{15}-\frac{1}{15}\leqslant{m_0}\leqslant250\cdot\frac{14}{15}+\frac{1}{15}
откуда 233,\!26\leqslant{m_0}\leqslant234,\!26 . Следовательно, наивероятнейшее число изделий, удовлетворяющих требованиям стандарта, в партии из 250 шт. равно 234. Подставляя данные в формулу (3.5), вычисляем вероятность наличия в партии наивероятнейшего числа изделий:
P_{234,250}\approx\frac{1}{\sqrt{2\pi\cdot250\cdot\frac{14}{15}\cdot\frac{1}{15}}}\approx0,\!101
Локальная теорема Лапласа
Пользоваться формулой Бернулли при больших значениях n очень трудно. Например, если n=50,\,m=30,\,p=0,\!1 , то для отыскания вероятности P_{30,50} надо вычислить значение выражения
P_{30,50}=\frac{50!}{30!\cdot20!}\cdot(0,\!1)^{30}\cdot(0,\!9)^{20}
Естественно, возникает вопрос: нельзя ли вычислить интересующую вероятность, не используя формулу Бернулли? Оказывается, можно. Локальная теорема Лапласа дает асимптотическую формулу, которая позволяет приближенно найти вероятность появления событий ровно m раз в n испытаниях, если число испытаний достаточно велико.
Теорема 3.1. Если вероятность p появления события A в каждом испытании постоянна и отлична от нуля и единицы, то вероятность P_{m,n} того, что событие A появится в n испытаниях ровно m раз, приближенно равна (тем точнее, чем больше n ) значению функции
Y=\frac{1}{\sqrt{npq}}\frac{e^{-x^2/2}}{\sqrt{2\pi}}=\frac{\varphi(x)}{\sqrt{npq}} при .
Существуют таблицы, которые содержат значения функции \varphi(x)=\frac{1}{\sqrt{2\pi}}\,e^{-x^2/2}} , соответствующие положительным значениям аргумента x . Для отрицательных значений аргумента используют те же таблицы, так как функция \varphi(x) четна, т. е. \varphi(-x)=\varphi(x) .
Итак, приближенно вероятность того, что событие A появится в n испытаниях ровно m раз,
P_{m,n}\approx\frac{1}{\sqrt{npq}}\,\varphi(x), где x=\frac{m-np}{\sqrt{npq}} .
Пример 3. Найти вероятность того, что событие A наступит ровно 80 раз в 400 испытаниях, если вероятность появления события A в каждом испытании равна 0,2.
Решение. По условию n=400,\,m=80,\,p=0,\!2,\,q=0,\!8 . Воспользуемся асимптотической, формулой Лапласа:
P_{80,400}\approx\frac{1}{\sqrt{400\cdot0,\!2\cdot0,\!8}}\,\varphi(x)=\frac{1}{8}\,\varphi(x).
Вычислим определяемое данными задачи значение x :
X=\frac{m-np}{\sqrt{npq}}=\frac{80-400\cdot0,\!2}{8}=0.
По таблице прил, 1 находим \varphi(0)=0,\!3989 . Искомая вероятность
P_{80,100}=\frac{1}{8}\cdot0,\!3989=0,\!04986.
Формула Бернулли приводит примерно к такому же результату (выкладки ввиду их громоздкости опущены):
P_{80,100}=0,\!0498.
Интегральная теорема Лапласа
Предположим, что проводится n независимых испытаний, в каждом из которых вероятность появления события A постоянна и равна p . Необходимо вычислить вероятность P_{(m_1,m_2),n} того, что событие A появится в n испытаниях не менее m_1 и не более m_2 раз (для краткости будем говорить "от m_1 до m_2 раз"). Это можно сделать с помощью интегральной теоремы Лапласа.
Теорема 3.2. Если вероятность p наступления события A в каждом испытании постоянна и отлична от нуля и единицы, то приближенно вероятность P_{(m_1,m_2),n} того, что событие A появится в испытаниях от m_1 до m_2 раз,
P_{(m_1,m_2),n}\approx\frac{1}{\sqrt{2\pi}}\int\limits_{x"}^{x""}e^{-x^2/2}\,dx, где .
При решении задач, требующих применения интегральной теоремы Лапласа, пользуются специальными таблицами, так как неопределенный интеграл \int{e^{-x^2/2}\,dx} не выражается через элементарные функции. Таблица для интеграла \Phi(x)=\frac{1}{\sqrt{2\pi}}\int\limits_{0}^{x}e^{-z^2/2}\,dz приведена в прил. 2, где даны значения функции \Phi(x) для положительных значений x , для x<0 используют ту же таблицу (функция \Phi(x) нечетна, т. е. \Phi(-x)=-\Phi(x) ). Таблица содержит значения функции \Phi(x) лишь для x\in ; для x>5 можно принять \Phi(x)=0,\!5 .
Итак, приближенно вероятность того, что событие A появится в n независимых испытаниях от m_1 до m_2 раз,
P_{(m_1,m_2),n}\approx\Phi(x"")-\Phi(x"), где x"=\frac{m_1-np}{\sqrt{npq}};~x""=\frac{m_2-np}{\sqrt{npq}} .
Пример 4. Вероятность того, что деталь изготовлена с нарушениями стандартов, p=0,\!2 . Найти вероятность того, что среди 400 случайно отобранных деталей нестандартных окажется от 70 до 100 деталей.
Решение. По условию p=0,\!2,\,q=0,\!8,\,n=400,\,m_1=70,\,m_2=100 . Воспользуемся интегральной теоремой Лапласа:
P_{(70,100),400}\approx\Phi(x"")-\Phi(x").
Вычислим пределы интегрирования:
нижний
X"=\frac{m_1-np}{\sqrt{npq}}=\frac{70-400\cdot0,\!2}{\sqrt{400\cdot0,\!2\cdot0,\!8}}=-1,\!25,
верхний
X""=\frac{m_2-np}{\sqrt{npq}}=\frac{100-400\cdot0,\!2}{\sqrt{400\cdot0,\!2\cdot0,\!8}}=2,\!5,
Таким образом
P_{(70,100),400}\approx\Phi(2,\!5)-\Phi(-1,\!25)=\Phi(2,\!5)+\Phi(1,\!25).
По таблице прил. 2 находим
\Phi(2,\!5)=0,\!4938;~~~~~\Phi(1,\!25)=0,\!3944.
Искомая вероятность
P_{(70,100),400}=0,\!4938+0,\!3944=0,\!8882.
Применение интегральной теоремы Лапласа
Если число m (число появлений события A при n независимых испытаниях) будет изменяться от m_1 до m_2 , то дробь \frac{m-np}{\sqrt{npq}} будет изменяться от \frac{m_1-np}{\sqrt{npq}}=x" до \frac{m_2-np}{\sqrt{npq}}=x"" . Следовательно, интегральную теорему Лапласа можно записать и так:
P\left\{x"\leqslant\frac{m-np}{\sqrt{npq}}\leqslant{x""}\right\}=\frac{1}{\sqrt{2\pi}}\int\limits_{x"}^{x""}e^{-x^2/2}\,dx.
Поставим задачу найти вероятность того, что отклонение относительной частоты \frac{m}{n} от постоянной вероятности p по абсолютной величине не превышает заданного числа \varepsilon>0 . Другими словами, найдем вероятность осуществления неравенства \left|\frac{m}{n}-p\right|\leqslant\varepsilon , что то же самое, -\varepsilon\leqslant\frac{m}{n}-p\leqslant\varepsilon . Эту вероятность будем обозначать так: P\left\{\left|\frac{m}{n}-p\right|\leqslant\varepsilon\right\} . С учетом формулы (3.6) для данной вероятности получаем
P\left\{\left|\frac{m}{n}-p\right|\leqslant\varepsilon\right\}\approx2\Phi\left(\varepsilon\,\sqrt{\frac{n}{pq}}\right).
Пример 5. Вероятность того, что деталь нестандартна, p=0,\!1 . Найти вероятность того, что среди случайно отобранных 400 деталей относительная частота появления нестандартных деталей отклонится от вероятности p=0,\!1 по абсолютной величине не более чем на 0,03.
Решение. По условию n=400,\,p=0,\!1,\,q=0,\!9,\,\varepsilon=0,\!03 . Требуется найти вероятность P\left\{\left|\frac{m}{400}-0,\!1\right|\leqslant0,\!03\right\} . Используя формулу (3.7), получаем
P\left\{\left|\frac{m}{400}-0,\!1\right|\leqslant0,\!03\right\}\approx2\Phi\left(0,\!03\sqrt{\frac{400}{0,\!1\cdot0,\!9}}\right)=2\Phi(2)
По таблице прил. 2 находим \Phi(2)=0,\!4772 , следовательно, 2\Phi(2)=0,\!9544 . Итак, искомая вероятность приближенно равна 0,9544. Смысл полученного результата таков: если взять достаточно большое число проб по 400 деталей в каждой, то примерно в 95,44% этих проб отклонение относительной частоты от постоянной вероятности p=0,\!1 по абсолютной величине не превысит 0,03.
Формула Пуассона для маловероятных событий
Если вероятность p наступления события в отдельном испытании близка к нулю, то даже при большом числе испытаний n , но при небольшом значении произведения np получаемые по формуле Лапласа значения вероятностей P_{m,n} оказываются недостаточно точными и возникает потребность в другой приближенной формуле.
Теорема 3.3. Если вероятность p наступления события A в каждом испытании постоянна, но мала, число независимых испытаний n достаточно велико, но значение произведения np=\lambda остается небольшим (не больше десяти), то вероятность того, что в этих испытаниях событие A наступит m раз,
P_{m,n}\approx\frac{\lambda^m}{m!}\,e^{-\lambda}.
Для упрощения расчетов с применением формулы Пуассона составлена таблица значений функции Пуассона \frac{\lambda^m}{m!}\,e^{-\lambda} (см. прил. 3).
Пример 6. Пусть вероятность изготовления нестандартной детали равна 0,004. Найти вероятность того, что среди 1000 деталей окажется 5 нестандартных.
Решение. Здесь n=1000,p=0,004,~\lambda=np=1000\cdot0,\!004=4 . Все три числа удовлетворяют требованиям теоремы 3.3, поэтому для нахождения вероятности искомого события P_{5,1000} применяем формулу Пуассона. По таблице значений функции Пуассона (прил. 3) при \lambda=4;m=5 получаем P_{5,1000}\approx0,\!1563 .
Найдем вероятность того же события по формуле Лапласа. Для этого сначала вычисляем значение x , соответствующее m=5 :
X=\frac{5-1000\cdot0,\!004}{\sqrt{1000\cdot0,\!004\cdot0,\!996}}\approx\frac{1}{1,\!996}\approx0,\!501.
Поэтому согласно формуле Лапласа искомая вероятность
P_{5,1000}\approx\frac{\varphi(0,\!501)}{1,\!996}\approx\frac{0,\!3519}{1,\!996}\approx0,\!1763
а согласно формуле Бернулли точное ее значение
P_{5,1000}=C_{1000}^{5}\cdot0,\!004^5\cdot0,\!996^{995}\approx0,\!1552.
Таким образом, относительная ошибка вычисления вероятностей P_{5,1000} по приближенной формуле Лапласа составляет
\frac{0,\!1763-0,\!1552}{0,\!1552}\approx0,\!196 , или 13,\!6\%
а по формуле Пуассона -
\frac{0,\!1563-0,\!1552}{0,\!1552}\approx0,\!007 , или 0,\!7\%
Т. е. во много раз меньше.
Перейти к следующему разделу
Одномерные случайные величины
В вашем браузере отключен Javascript.
Чтобы произвести расчеты, необходимо разрешить элементы ActiveX!
Не будем долго размышлять о высоком — начнем сразу с определения.
Схема Бернулли — это когда производится n однотипных независимых опытов, в каждом из которых может появиться интересующее нас событие A , причем известна вероятность этого события P (A ) = p. Требуется определить вероятность того, что при проведении n испытаний событие A появится ровно k раз.
Задачи, которые решаются по схеме Бернулли, чрезвычайно разнообразны: от простеньких (типа «найдите вероятность, что стрелок попадет 1 раз из 10») до весьма суровых (например, задачи на проценты или игральные карты). В реальности эта схема часто применяется для решения задач, связанных с контролем качества продукции и надежности различных механизмов, все характеристики которых должны быть известны до начала работы.
Вернемся к определению. Поскольку речь идет о независимых испытаниях, и в каждом опыте вероятность события A одинакова, возможны лишь два исхода:
- A — появление события A с вероятностью p;
- «не А» — событие А не появилось, что происходит с вероятностью q = 1 − p.
Важнейшее условие, без которого схема Бернулли теряет смысл — это постоянство. Сколько бы опытов мы ни проводили, нас интересует одно и то же событие A , которое возникает с одной и той же вероятностью p.
Между прочим, далеко не все задачи в теории вероятностей сводятся к постоянным условиям. Об этом вам расскажет любой грамотный репетитор по высшей математике. Даже такое нехитрое дело, как вынимание разноцветных шаров из ящика, не является опытом с постоянными условиями. Вынули очередной шар — соотношение цветов в ящике изменилось. Следовательно, изменились и вероятности.
Если же условия постоянны, можно точно определить вероятность того, что событие A произойдет ровно k раз из n возможных. Сформулируем этот факт в виде теоремы:
Теорема Бернулли. Пусть вероятность появления события A в каждом опыте постоянна и равна р. Тогда вероятность того, что в n независимых испытаниях событие A появится ровно k раз, рассчитывается по формуле:
где C n k — число сочетаний, q = 1 − p.
Эта формула так и называется: формула Бернулли. Интересно заметить, что задачи, приведенные ниже, вполне решаются без использования этой формулы. Например, можно применить формулы сложения вероятностей. Однако объем вычислений будет просто нереальным.
Задача. Вероятность выпуска бракованного изделия на станке равна 0,2. Определить вероятность того, что в партии из десяти выпущенных на данном станке деталей ровно k будут без брака. Решить задачу для k = 0, 1, 10.
По условию, нас интересует событие A выпуска изделий без брака, которое случается каждый раз с вероятностью p = 1 − 0,2 = 0,8. Нужно определить вероятность того, что это событие произойдет k раз. Событию A противопоставляется событие «не A », т.е. выпуск бракованного изделия.
Таким образом, имеем: n = 10; p = 0,8; q = 0,2.
Итак, находим вероятность того, что в партии все детали бракованные (k = 0), что только одна деталь без брака (k = 1), и что бракованных деталей нет вообще (k = 10):

Задача. Монету бросают 6 раз. Выпадение герба и решки равновероятно. Найти вероятность того, что:
- герб выпадет три раза;
- герб выпадет один раз;
- герб выпадет не менее двух раз.
Итак, нас интересует событие A , когда выпадает герб. Вероятность этого события равна p = 0,5. Событию A противопоставляется событие «не A », когда выпадает решка, что случается с вероятностью q = 1 − 0,5 = 0,5. Нужно определить вероятность того, что герб выпадет k раз.
Таким образом, имеем: n = 6; p = 0,5; q = 0,5.
Определим вероятность того, что герб выпал три раза, т.е. k = 3:
Теперь определим вероятность того, что герб выпал только один раз, т.е. k = 1:
Осталось определить, с какой вероятностью герб выпадет не менее двух раз. Основная загвоздка — во фразе «не менее». Получается, что нас устроит любое k , кроме 0 и 1, т.е. надо найти значение суммы X = P 6 (2) + P 6 (3) + ... + P 6 (6).
Заметим, что эта сумма также равна (1 − P 6 (0) − P 6 (1)), т.е. достаточно из всех возможных вариантов «вырезать» те, когда герб выпал 1 раз (k = 1) или не выпал вообще (k = 0). Поскольку P 6 (1) нам уже известно, осталось найти P 6 (0):

Задача. Вероятность того, что телевизор имеет скрытые дефекты, равна 0,2. На склад поступило 20 телевизоров. Какое событие вероятнее: что в этой партии имеется два телевизора со скрытыми дефектами или три?
Интересующее событие A — наличие скрытого дефекта. Всего телевизоров n = 20, вероятность скрытого дефекта p = 0,2. Соответственно, вероятность получить телевизор без скрытого дефекта равна q = 1 − 0,2 = 0,8.
Получаем стартовые условия для схемы Бернулли: n = 20; p = 0,2; q = 0,8.
Найдем вероятность получить два «дефектных» телевизора (k = 2) и три (k = 3):
\[\begin{array}{l}{P_{20}}\left(2 \right) = C_{20}^2{p^2}{q^{18}} = \frac{{20!}}{{2!18!}} \cdot {0,2^2} \cdot {0,8^{18}} \approx 0,137\\{P_{20}}\left(3 \right) = C_{20}^3{p^3}{q^{17}} = \frac{{20!}}{{3!17!}} \cdot {0,2^3} \cdot {0,8^{17}} \approx 0,41\end{array}\]
Очевидно, P 20 (3) > P 20 (2), т.е. вероятность получить три телевизора со скрытыми дефектами больше вероятности получить только два таких телевизора. Причем, разница неслабая.
Небольшое замечание по поводу факториалов. Многие испытывают смутное ощущение дискомфорта, когда видят запись «0!» (читается «ноль факториал»). Так вот, 0! = 1 по определению.
P . S . А самая большая вероятность в последней задаче — это получить четыре телевизора со скрытыми дефектами. Подсчитайте сами — и убедитесь.
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест к любым данным без проверки их нормальности. Такая небрежность способна порождать серьёзные ошибки и превращать «поклонников» теста в ненавистников статистики. Попробуем поставить токи над i и разобраться, какие модели случайных величин должны использоваться для описания тех или иных явлений и какая между ними существует генетическая связь.
В первую очередь, данный материал будет интересен студентам, изучающим теорию вероятностей и статистику, хотя и «зрелые» специалисты смогут его использовать в качестве справочника. В одной из следующих работ я покажу пример использования статистики для построения теста оценки значимости показателей биржевых торговых стратегий.
В работе будут рассмотрены :
В конце статьи будет задан для размышлений. Свои размышления по этому поводу я изложу в следующей статье.
Некоторые из приведённых непрерывных распределений являются частными случаями .
Дискретные распределения
Дискретные распределения используются для описания событий с недифференцируемыми характеристиками, определёнными в изолированных точках. Проще говоря, для событий, исход которых может быть отнесён к некоторой дискретной категории: успех или неудача, целое число (например, игра в рулетку, в кости), орёл или решка и т.д.Описывается дискретное распределение вероятностью наступления каждого из возможных исходов события. Как и для любого распределения (в том числе непрерывного) для дискретных событий определены понятия матожидания и дисперсии. Однако, следует понимать, что матожидание для дискретного случайного события - величина в общем случае нереализуемая как исход одиночного случайного события, а скорее как величина, к которой будет стремиться среднее арифметическое исходов событий при увеличении их количества.
В моделировании дискретных случайных событий важную роль играет комбинаторика, так как вероятность исхода события можно определить как отношение количества комбинаций, дающих требуемый исход к общему количеству комбинаций. Например: в корзине лежат 3 белых мяча и 7 чёрных. Когда мы выбираем из корзины 1 мяч, мы можем сделать это 10-ю разными способами (общее количество комбинаций), но только 3 варианта, при которых будет выбран белый мяч (3 комбинации, дающие требуемый исход). Таким образом, вероятность выбрать белый мяч: ().
Следует также отличать выборки с возвращением и без возвращения. Например, для описания вероятности выбора двух белых мячей важно определить, будет ли первый мяч возвращён в корзину. Если нет, то мы имеем дело с выборкой без возвращения () и вероятность будет такова: - вероятность выбрать белый мяч из начальной выборки умноженная на вероятность снова выбрать белый мяч из оставшихся в корзине. Если же первый мяч возвращается в корзину, то это выборка с возвращением (). В этом случае вероятность выбора двух белых мячей составит .
Если несколько формализовать пример с корзиной следующим образом: пусть исход события может принимать одно из двух значений 0 или 1 с вероятностями и соответственно, тогда распределение вероятности получения каждого из предложенных исходов будет называться распределение Бернулли:
По сложившейся традиции, исход со значением 1 называется «успех», а исход со значением 0 - «неудача». Очевидно, что получение исхода «успех или неудача» наступает с вероятностью .
Матожидание и дисперсия распределения Бернулли:
Количество успехов в испытаниях, исход которых распределен по с вероятностью успеха (пример с возвращением мячей в корзину), описывается биномиальным распределением:
По другому можно сказать, что биномиальное распределение описывает сумму из независимых случайных величин, умеющих распределение с вероятностью успеха .
Матожидание и дисперсия:
Биномиальное распределение справедливо только для выборки с возвращением, то есть, когда вероятность успеха остаётся постоянной для всей серии испытаний.
Если величины и имеют биномиальные распределения с параметрами и соответственно, то их сумма также будет распределена биномиально с параметрами .
Представим ситуацию, что мы вытягиваем мячи из корзины и возвращаем обратно до тех пор, пока не будет вытянут белый шар. Количество таких операций описывается геометрическим распределением. Иными словами: геометрическое распределение описывает количество испытаний до первого успеха при вероятности наступления успеха в каждом испытании . Если подразумевается номер испытания, в котором наступил успех, то геометрическое распределение будет описываться следующей формулой:
Матожидание и дисперсия геометрического распределения:
Геометрическое распределение генетически связано с распределением, которое описывает непрерывную случайную величину: время до наступления события, при постоянной интенсивности событий. Геометрическое распределение также является частным случаем .
Распределение Паскаля является обобщением распределения: описывает распределение количества неудач в независимых испытаниях, исход которых распределен по с вероятностью успеха до наступления успехов в сумме. При , мы получим распределение для величины .
где - число сочетаний из по .
Матожидание и дисперсия отрицательного биномиального распределения:
Сумма независимых случайных величин, распределённых по Паскалю, также распределена по Паскалю: пусть имеет распределение , а - . Пусть также и независимы, тогда их сумма будет иметь распределение
До сих пор мы рассматривали примеры выборок с возвращением, то есть, вероятность исхода не менялась от испытания к испытанию.
Теперь рассмотрим ситуацию без возвращения и опишем вероятность количества успешных выборок из совокупности с заранее известным количеством успехов и и неудач (заранее известное количество белых и чёрных мячей в корзине, козырных карт в колоде, бракованных деталей в партии и т.д.).
Пусть общая совокупность содержит объектов, из них помечены как «1», а как «0». Будем считать выбор объекта с меткой «1», как успех, а с меткой «0» как неудачу. Проведём n испытаний, причём выбранные объектв больше не будут участвовать в дальнейших испытаниях. Вероятность наступления успехов будет подчиняться гипергеометрическому распределению:
где - число сочетаний из по .
Матожидание и дисперсия:
Распределение Пуассона

(взято отсюда)
Распределение Пуассона значительно отличается от рассмотренных выше распределений своей «предметной» областью: теперь рассматривается не вероятность наступления того или иного исхода испытания, а интенсивность событий, то есть среднее количество событий в единицу времени.
Распределение Пуассона описывает вероятность наступления независимых событий за время при средней интенсивности событий :
Матожидание и дисперсия распределения Пуассона:
Дисперсия и матожидание распределения Пуассона тождественно равны.
Распределение Пуассона в сочетании с , описывающим интервалы времени между наступлениями независимых событий, составляют математическую основу теории надёжности.
Плотность вероятности произведения случайных величин x и y () с распределениями и может быть вычислена следующим образом:
Некоторые из приведённых ниже распределений являются частными случаями распределения Пирсона, которое, в свою очередь, является решением уравнения:
где и - параметры распределения. Известны 12 типов распределения Пирсона, в зависимости от значений параметров.
Распределения, которые будут рассмотрены в этом разделе, имеют тесные взаимосвязи друг с другом. Эти связи выражаются в том, что некоторые распределения являются частными случаями других распределений, либо описывают преобразования случайных величин, имеющих другие распределения.
На приведённой ниже схеме отражены взаимосвязи между некоторыми из непрерывных распределений, которые будут рассмотрены в настоящей работе. На схеме сплошными стрелками показано преобразование случайных величин (начало стрелки указывает на изначальное распределение, конец стрелки - на результирующее), а пунктирными - отношение обобщения (начало стрелки указывает на распределение, являющееся частным случаем того, на которое указывает конец стрелки). Для частных случаев распределения Пирсона над пунктирными стрелками указан соответствующий тип распределения Пирсона.

Предложенный ниже обзор распределений охватывает многие случаи, которые встречаются в анализе данных и моделировании процессов, хотя, конечно, и не содержит абсолютно все известные науке распределения.
Нормальное распределение (распределение Гаусса)

(взято отсюда)
Плотность вероятности нормального распределения с параметрами и описывается функцией Гаусса:
Если и , то такое распределение называется стандартным.
Матожидание и дисперсия нормального распределения:
Область определения нормального распределения - множество дествительных чисел.
Нормальное распределение является распределение типа VI.
Сумма квадратов независимых нормальных величин имеет , а отношение независимых Гауссовых величин распределено по .
Нормальное распределение является бесконечно делимым: сумма нормально распределенных величин и с параметрами и соответственно также имеет нормальное распределение с параметрами , где и .
Нормальное распределение хорошо моделирует величины, описывающие природные явления, шумы термодинамической природы и погрешности измерений.
Кроме того, согласно центральной предельной теореме, сумма большого количества независимых слагаемых одного порядка сходится к нормальному распределению, независимо от распределений слагаемых. Благодаря этому свойству, нормальное распределение популярно в статистическом анализе, многие статистические тесты рассчитаны на нормально распределенные данные.
На бесконечной делимости нормального распределении основан z-тест. Этот тест используется для проверки равенства матожидания выборки нормально распределённых величин некоторому значению. Значение дисперсии должно быть известно . Если значение дисперсии неизвестно и рассчитывается на основании анализируемой выборки, то применяется t-тест, основанный на .
Пусть у нас имеется выборка объёмом n независимых нормально распределенных величин из генеральной совокупности со стандартным отклонением выдвинем гипотезу, что . Тогда величина будет иметь стандартное нормальное распределение. Сравнивая полученное значение z с квантилями стандартного распределения можно принимать или отклонять гипотезу с требуемым уровнем значимости.
Благодаря широкой распространённости распределения Гаусса, многие, не очень хорошо знающие статистику исследователи забывают проверять данные на нормальность, либо оценивают график плотности распределения «на глазок», слепо полагая, что имеют дело с Гауссовыми данными. Соответственно, смело применяя тесты, предназначенные для нормального распределения и получая совершенно некорректные результаты. Наверное, отсюда и пошла молва про статистику как самый страшный вид лжи.
Рассмотрим пример: нам надо измерить сопротивления набора резистров некоторого номинала. Сопротивление имеет физическую природу, логично предположить, что распределение отклонений сопротивления от номинала будет нормальным. Меряем, получаем колоколообразную функцию плотности вероятности для измеренных значений с модой в окрестности номинала резистров. Это нормальное распределение? Если да, то будем искать бракованные резистры используя , либо z-тест, если нам заранее известна дисперсия распределения. Думаю, что многие именно так и поступят.
Но давайте внимательнее посмотрим на технологию измерения сопротивления: сопротивление определяется как отношение приложенного напряжения к протекающему току. Ток и напряжение мы измеряли приборами, которые, в свою очередь, имеют нормально распределенные погрешности. То есть, измеренные значения тока и напряжения - это нормально распределенные случайные величины с матожиданиями, соответствующими истинным значениям измеряемых величин. А это значит, что полученные значения сопротивления распределены по , а не по Гауссу.
Распределение описывает сумму квадратов случайных величин , каждая из которых распределена по стандартному нормальному закону :
Где - число степеней свободы, .
Матожидание и дисперсия распределения :
Область определения - множество неотрицательных натуральных чисел. является бесконечно делимым распределением. Если и - распределены по и имеют и степеней свободы соответственно, то их сумма также будет распределена по и иметь степеней свободы.
Является частным случаем (а следовательно, распределением типа III) и обобщением . Отношение величин, распределенных по распределено по .
На распределении основан критерий согласия Пирсона. с помощью этого критерия можно проверять достоверность принадлежности выборки случайной величины некоторому теоретическому распределению.
Предположим, что у нас имеется выборка некоторой случайной величины . На основании этой выборки рассчитаем вероятности попадания значений в интервалов (). Пусть также есть предположение об аналитическом выражении распределения, в соответствие с которым, вероятности попадания в выбранные интервалы должны составлять . Тогда величины будут распределены по нормальному закону.
Приведем к стандартному нормальному распределению: ,
где и .
Полученные величины имеют нормальное распределение с параметрами (0, 1), а следовательно, сумма их квадратов распределена по с степенью свободы. Снижение степени свободы связано с дополнительным ограничением на сумму вероятностей попадания значений в интервалы: она должна быть равна 1.
Сравнивая значение с квантилями распределения можно принять или отклонить гипотезу о теоретическом распределении данных с требуемым уровнем значимости.
Распределение Стьюдента используется для проведения t-теста: теста на равенство матожидания выборки распределённых случайных величин некоторому значению, либо равенства матожиданий двух выборок с одинаковой дисперсией (равенство дисперсий необходимо проверять ). Распределение Стьюдента описывает отношение распределённой случайной величины к величине, распределённой по .
Пусть и независимые случайные величины, имеющие со степенями свободы и соответственно. Тогда величина будет иметь распределение Фишера со степенями свободы , а величина - распределение Фишера со степенями свободы .
Распределение Фишера определено для действительных неотрицательных аргументов и имеет плотность вероятности:
Матожидание и дисперсия распределения Фишера:
Матожидание определено для , а диспересия - для .
На распределении Фишера основан ряд статистических тестов, таких как оценка значимости параметров регрессии, тест на гетероскедастичность и тест на равенство дисперсий выборок (f-тест, следует отличать от точного теста Фишера).
F-тест: пусть имеются две независимые выборки и распределенных данных объёмами и соответственно. Выдвинем гипотезу о равенстве дисперсий выборок и проверим её статистически.
Рассчитаем величину . Она будет иметь распределение Фишера со степенями свободы .
Сравнивая значение с квантилями соответствующего распределения Фишера, мы можем принять или отклонить гипотезу о равенстве дисперсий выборок с требуемым уровнем значимости.
Экспоненциальное (показательное) распределение и распределение Лапласа (двойное экспоненциальное, двойное показательное)

(взято отсюда)
Экспоненциальное распределение описывает интервалы времени между независимыми событиями, происходящими со средней интенсивностью . Количество наступлений такого события за некоторый отрезок времени описывается дискретным . Экспоненциальное распределение вместе с составляют математическую основу теории надёжности.
Кроме теории надёжности, экспоненциальное распределение применяется в описании социальных явлений, в экономике, в теории массового обслуживания, в транспортной логистике - везде, где необходимо моделировать поток событий.
Экспоненциальное распределение является частным случаем (для n=2), а следовательно, и . Так-как экспоненциально распределённая величина является величиной хи-квадрат с 2-мя степенями свободы, то она может быть интерпретирована как сумма квадратов двух независимых нормально распределенных величин.
Кроме того, экспоненциальное распределение является честным случаем
Формула Бернулли - формула в теории вероятностей , позволяющая находить вероятность появления события A {\displaystyle A} при независимых испытаниях. Формула Бернулли позволяет избавиться от большого числа вычислений - сложения и умножения вероятностей - при достаточно большом количестве испытаний. Названа в честь выдающегося швейцарского математика Якоба Бернулли , который вывел эту формулу.
Энциклопедичный YouTube
1 / 3
✪ Теория вероятностей. 22. Формула Бернулли. Решение задач
✪ Формула Бернулли
✪ 20 Повторение испытаний Формула Бернулли
Субтитры
Формулировка
Теорема. Если вероятность p {\displaystyle p} наступления события A {\displaystyle A} в каждом испытании постоянна, то вероятность P k , n {\displaystyle P_{k,n}} того, что событие A {\displaystyle A} наступит ровно k {\displaystyle k} раз в n {\displaystyle n} независимых испытаниях, равна: P k , n = C n k ⋅ p k ⋅ q n − k {\displaystyle P_{k,n}=C_{n}^{k}\cdot p^{k}\cdot q^{n-k}} , где q = 1 − p {\displaystyle q=1-p} .
Доказательство
Пусть проводится n {\displaystyle n} независимых испытаний, причём известно, что в результате каждого испытания событие A {\displaystyle A} наступает с вероятностью P (A) = p {\displaystyle P\left(A\right)=p} и, следовательно, не наступает с вероятностью P (A ¯) = 1 − p = q {\displaystyle P\left({\bar {A}}\right)=1-p=q} . Пусть, так же, в ходе испытаний вероятности p {\displaystyle p} и q {\displaystyle q} остаются неизменными. Какова вероятность того, что в результате n {\displaystyle n} независимых испытаний, событие A {\displaystyle A} наступит ровно k {\displaystyle k} раз?
Оказывается можно точно подсчитать число "удачных" комбинаций исходов испытаний, для которых событие A {\displaystyle A} наступает k {\displaystyle k} раз в n {\displaystyle n} независимых испытаниях, - в точности это количество сочетаний из n {\displaystyle n} по k {\displaystyle k} :
C n (k) = n ! k ! (n − k) ! {\displaystyle C_{n}(k)={\frac {n!}{k!\left(n-k\right)!}}} .
В то же время, так как все испытания независимы и их исходы несовместимы (событие A {\displaystyle A} либо наступает, либо нет), то вероятность получения "удачной" комбинации в точности равна: .
Окончательно, для того чтобы найти вероятность того, что в n {\displaystyle n} независимых испытаниях событие A {\displaystyle A} наступит ровно k {\displaystyle k} раз, нужно сложить вероятности получения всех "удачных" комбинаций. Вероятности получения всех "удачных" комбинаций одинаковы и равны p k ⋅ q n − k {\displaystyle p^{k}\cdot q^{n-k}} , количество "удачных" комбинаций равно C n (k) {\displaystyle C_{n}(k)} , поэтому окончательно получаем:
P k , n = C n k ⋅ p k ⋅ q n − k = C n k ⋅ p k ⋅ (1 − p) n − k {\displaystyle P_{k,n}=C_{n}^{k}\cdot p^{k}\cdot q^{n-k}=C_{n}^{k}\cdot p^{k}\cdot (1-p)^{n-k}} .
Последнее выражение есть не что иное, как Формула Бернулли. Полезно также заметить, что в силу полноты группы событий, будет справедливо:
∑ k = 0 n (P k , n) = 1 {\displaystyle \sum _{k=0}^{n}(P_{k,n})=1} .
Производится n опытов по схеме Бернулли с вероятностью успеха p . Пусть X - число успехов. Случайная величина X имеет область значений {0,1,2,...,n}. Вероятности этих значений можно найти по формуле:
, где C m n - число сочетаний из n по m . ![]()
Ряд распределения имеет вид:
| x | 0 | 1 | ... | m | n |
| p | (1-p) n | np(1-p) n-1 | ... | C m n p m (1-p) n-m | p n |
Назначение сервиса . Онлайн-калькулятор используется для построения биноминальным ряда распределения и вычисления всех характеристик ряда: математического ожидания, дисперсии и среднеквадратического отклонения. Отчет с решением оформляется в формате Word (пример).
Видеоинструкция
Схема испытаний Бернулли
Числовые характеристики случайной величины, распределенной по биноминальному закону
Математическое ожидание случайной величины Х, распределенной по биноминальному закону.M[X]=np
Дисперсия случайной величины Х, распределенной по биноминальному закону.
D[X]=npq
Пример №1
. Изделие может оказаться дефектным с вероятностью р = 0.3 каждое. Из партии выбирают три изделия. Х – число дефектных деталей среди отобранных. Найти (все ответы вводить в виде десятичных дробей): а) ряд распределения Х; б) функцию распределения F(x) .
Решение
. Случайная величина X имеет область значений {0,1,2,3}.
Найдем ряд распределения X.
P 3 (0) = (1-p) n = (1-0.3) 3 = 0.34
P 3 (1) = np(1-p) n-1 = 3(1-0.3) 3-1 = 0.44
P 3 (3) = p n = 0.3 3 = 0.027
| x i | 0 | 1 | 2 | 3 |
| p i | 0.34 | 0.44 | 0.19 | 0.027 |
Математическое ожидание находим по формуле M[X]= np = 3*0.3 = 0.9
Проверка: m = ∑x i p i .
Математическое ожидание M[X] .
M[x] = 0*0.34 + 1*0.44 + 2*0.19 + 3*0.027 = 0.9
Дисперсию находим по формуле D[X]=npq = 3*0.3*(1-0.3) = 0.63
Проверка: d = ∑x 2 i p i - M[x] 2 .
Дисперсия D[X] .
D[X] = 0 2 *0.34 + 1 2 *0.44 + 2 2 *0.19 + 3 2 *0.027 - 0.9 2 = 0.63
Среднее квадратическое отклонение σ(x) .
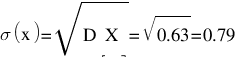
Функция распределения F(X) .
F(xF(0F(1F(2F(x>3) = 1
- Вероятность появления события в одном испытании равна 0.6 . Производится 5 испытаний. Составить закон распределения случайной величины Х – числа появлений события.
- Составить закон распределения случайной величины Х числа попаданий при четырех выстрелах, если вероятность попадания в цель при одном выстреле равна 0.8 .
- Монету подбрасывают 7 раз. Найти математическое ожидание и дисперсию числа появлений герба. Примечание: здесь вероятность появление герба равна p = 1/2 (т.к. у монеты две стороны).
Пример №2 . Вероятность появления события в отдельном испытании равна 0.6 . Применяя теорему Бернулли, определите число независимых испытаний, начиная с которого вероятность отклонения частоты события от его вероятности по абсолютной величине меньше 0.1 , больше 0.97 . (Ответ: 801)
Пример №3
. Студенты выполняют контрольную работу в классе информатики. Работа состоит из трех задач. Для получения хорошей оценки нужно найти правильные ответы не меньше чем на две задачи. К каждой задаче дается 5 ответов из которых только одна правильная. Студент выбирает ответ наугад. Какая вероятность того, что он получит хорошую оценку?
Решение
. Вероятность правильно ответить на вопрос: p=1/5=0.2; n=3.
Эти данные необходимо ввести в калькулятор. В ответ см. для P(2)+P(3).
Пример №4 . Вероятность попадания стрелка в мишень при одном выстреле равна (m+n)/(m+n+2) . Производится n+4 выстрела. Найти вероятность того, что он промахнется не более двух раз.
Примечание . Вероятность того, что он промахнется не более двух раз включает в себя следующие события: ни разу не промахнется P(4), промахнется один раз P(3), промахнется два раза P(2).
Пример №5 . Определите распределение вероятностей числа отказавших самолётов, если влетает 4 машины. Вероятность безотказной работы самолета Р=0.99 . Число отказавших в каждом вылете самолётов распределено по биноминальному закону.